

Amazon Athena, Explained: What is it, and When Should I Use it?
Sep 11, 2023 • 8 Minute Read

So, you’re a data analyst! Depending on who you ask, these two words carry different connotations on how you spend your time.
To your friends, you’re that mysterious professional who spends their day doing artificial intelligence or machine learning, and the go-to person for every new trend from metaverse to Bitcoin. Each time they read an article like “5 ways big data will transform the world”, they immediately think of you.
Depending on your family’s technological proficiency, at least one member — if not more — thinks they need your blessings with any computer purchase. To your boss, you are most likely the visual reports master.
Meanwhile, in reality, you spend most of your career querying data and analyzing query results before you get anywhere near drawing graphs, building data models, or deducing any data-driven insights. And before you get to querying, there’s a lot of set up to do!

That’s why there was a lot of excitement in the data analysis and data science communities when Amazon Web Services (AWS) launched Amazon Athena in 2016, which promised to get rid of some of these hurdles. In this article, we delve into what Amazon Athena is, its strengths and weaknesses, and how you can use it.
What is Amazon Athena? And what’s in it for data analysts?
Amazon Athena is an ANSI-standard query tool that allows you to query data, including big data, in two straightforward steps:
- Connecting directly to data sources such as Amazon Simple Storage Service (S3)
- Using the AWS intuitive GUI option or the command line to interactively query data using the Structured Query Language (SQL)
The entire process is streamlined regardless of how big the data is because AWS Athena is serverless. This means Athena allows you to skip various complicated tasks including:
- Setting up the Infrastructure – Because it’s serverless, you don’t need to manage setting up servers or clusters.
- Loading the Data – You don’t need to have to extract, transform, or load (ETL) the data into Amazon Athena to be able to query data as it connects directly to your data source.
- Structuring the Data – Athena uses schema-on-read making it ideal for reading structured, semi-structured, and unstructured data.
All of the above translates to the instant querying capability! Athena empowers you as a data analyst to query data as soon as you or your firm obtains access to the source data.
On top of this, Athena's engineering makes it more accessible to business professionals and data stewards because Athena:
- Runs Standard SQL – Athena’s engine is built on Presto and runs standard ANSI SQL (Structured Query Language)
- Supports Multiple Data Formats – Supports standard data formats such as CSV, JSON, ORC, Avro, and Parquet. Athena supports all the file formats that data analysts typically analyze.
- Supports complex DDL statements including large joins, window functions, and arrays.
- Integrates well with business intelligence tools, thus simplifying the process of turning dry columnar data into visually appealing and more digestible reports.
What data sources can Athena Query?
Even though AWS primarily built Athena to query data sitting in AWS S3, you can use it to directly query other AWS services such as CloudTrail, DynamoDB, and DocumentDB. It can also connect to third-party vendors such as Snowflake, Oracle, and Microsoft SQL Server.
The table below summarizes the three data sources that Athena can directly query.
| AWS | Third Party | Custom |
| S3 | MySQL | Custom connection through Lambda |
| Amazon DynamoDB | PostgreSQL | |
| Amazon Redshift | PostgreSQL | |
| Amazon CloudWatch | Oracle | |
| Amazon DocumentDB | Microsoft Azure | |
| Amazon OpenSearch | Microsoft SQL Server | |
| Amazon Neptune | Google BigQuery | |
| Amazon Timestream | Snowflake | |
| AWS CMDB | Teradata | |
| Redis | ||
| Apache HBASE | ||
| Vertica | ||
| SAP HANA | ||
| Hortonworks | ||
| TPC-DS |
How much does AWS Athena cost?
In terms of pricing, Athena follows a pay-per-query pricing model where you only get charged for the amount of queried data. Athena costs $5/TB or 5 cents/10 GB.
What are Athena’s Limitations?
As robust and interactive Athena is, it has a few limitations to consider when assessing this tool for your needs, listed below.
Inconsistent performance
Athena doesn’t provide dedicated resources. Your queries share a pool of resources with other users in the same AWS region. Therefore, it is not ideal for applications where real-time results are required.
For the most part, Athena is fast, but you still need to keep in mind that the speed of the performance depends on other factors that aren’t always in your control.
Unpredictable costs
The pay-per-query model is a double-edged sword. If your queries are not optimized, or if you don’t have a well-thought partitioning strategy, Athena’s pricing model can become your foe.
First off, the costs add up pretty quickly. As a data analyst, you are familiar with how one query leads to the next, and before you know it, your SQL queries have scanned the entire database.
Secondly, without query optimization and proper partitioning strategy, you will query unnecessary data and end up paying avoidable charges.
Unsupported features
Despite its name, Athena is no goddess! It has some unsupported features, like:
- Not all DDL statements are supported
- SQL limitations (e.g.Athena doesn’t support stored procedures)
- Treating S3 as read-only (There is no built-in way to perform insert, update, or delete operations to data in S3)
Assuming none of those limitations are a deal breaker for your business needs, you're probably asking how to get started with this tool.
So with that wild guess, let’s jump to the next question …
How can I start using Amazon Athena?
To answer this question, let’s first understand how to get in the door and access Athena.
Accessing Athena
Athena can be accessed in several ways, some more complex than others, but as a data analyst, you’ll probably be interested in accessing it via the AWS Management Console or MySQL WorkBench.
AWS Management Console
Using the AWS Console, you can navigate to the Amazon Athena service to interact with its Query Editor. Once you write SQL queries in the editor and hit the Run button to execute, it returns most query results within seconds. This option is pretty sleek, and you can customize it to your preferences.
For a drive around the tool and a tutorial on customizing Athena Dashboard, check out the demos in my Introduction to Amazon Athena course.
MySQL WorkBench
Amazon Athena allows you to query data in it using MySQL interfaces such as MySQL WorkBench via a JDBC connection. For more on this option, check out this AWS tutorial.
Querying in Athena
So thus far, Athena sounds like a crafty magician that points to stuff only to pull out fluffy animals and white doves out of nowhere.

You point to data sitting in S3, and Athena comes back with an instant querying capability. But just like magicians use props and optical illusion to perform their shows, Athena uses underlying tables and schemas to perform querying on underlying data.
So, in the same process where you point to the data source, you will also need to define the schema for the file you are trying to query. Only then will Athena have the required metadata in the AWS GLUE Data Catalog. Without this catalog and the metadata, Athena wouldn’t have the slightest clue about the structure of the data.
So to query any data in Athena, Athena needs its metadata which gets organized in AWS in this hierarchical fashion:
- Data Catalog
- Database
- Table
Therefore, in addition to pointing to the data, you need to set up the database and build a table for each dataset you plan to query. In other words, you need to perform the three steps below to query in Athena:
- Point to the data source for example an AWS S3 Bucket.
- Create a database and create a table per dataset/file. The tables will automatically get stored in the AWS Glue catalog.
- Query the data using SQL in the Athena query editor.
There are two mechanisms to build the tables for Athena as follows:
- Define the Schema – You define the schema by explicitly providing the names and datatypes of the columns. This option is free of charge.
- Detect the Schema – You detect the schema using the AWS Glue service. But keep in mind that there are costs associated with the Glue service.
The heavy lifting lies in building those tables, and it doesn’t matter which option you go with so long your schema matches precisely the schema of your source files for things to work. You must ensure that the order of the columns and the data types in the schema matches the order in the source file. For example, if your source file has an ID, PRICE, BED, BATH, and SQFT columns, you must reflect the exact structure in your schema.
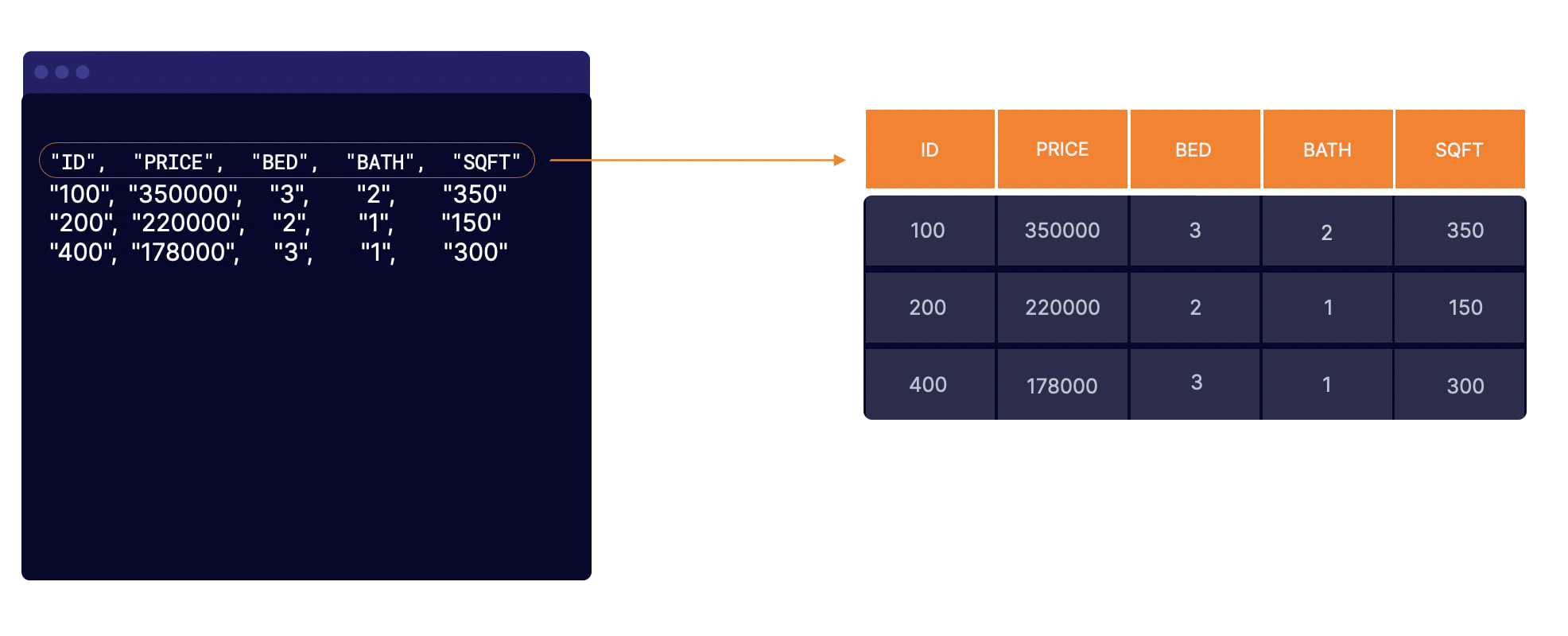
For a demo tutorial showing you both ways for building tables in Athena and much more, check out my new Introduction to Amazon Athena course.

Advance your tech skills today
Access courses on AI, cloud, data, security, and more—all led by industry experts.
